What Is Classification in Data Mining?
The process of data mining involves the analysis of databases. Each database is unique in its data type and handles a defied data model. To create an optimal solution, you must first separate the database into different categories.

What Is Classification in Data Mining?
The process of data mining involves the analysis of databases. Each database is unique in its data type and handles a defied data model. To create an optimal solution, you must first separate the database into different categories. For example, you may use a classification scheme to group data related to loan applications into categories that represent the degree of credit risk for each customer. This technique relies on patterns within the data and helps you organize the data in logical groups.
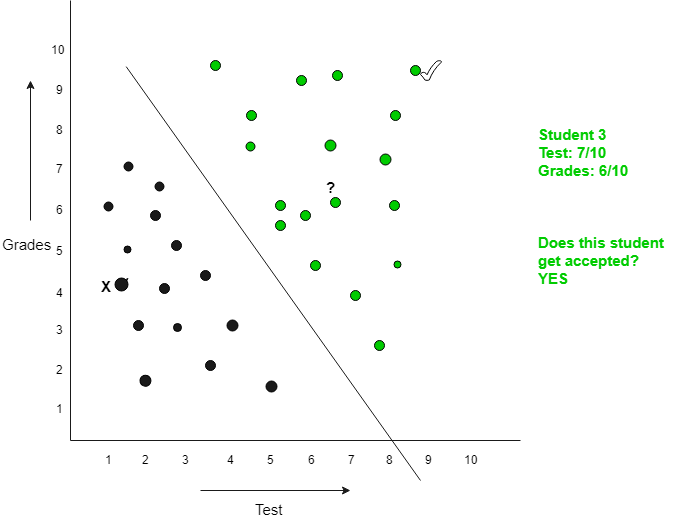
Classification in Data Mining:
Classification in data mining involves modifying algorithms. This method is also known as supervised learning. The purpose of the process is to link a variable of interest to the required variables. The variable of interest is a qualitative variable, so the algorithm used to classify the data consists of many variables. These observations are called instances. If the algorithms are accurate, they can predict a target class. In addition to predicting the target class, the algorithms also help you find patterns in the data.
The best way to understand the concept of classification is to understand how it can help your company in a variety of ways. This article will discuss the different types of data mining and how you can apply them to your business. The most common category is "prediction" and the two methods are related to each other. For example, if you want to forecast that the temperature in a city will be 30 degrees Celsius, you would use a classification model that forecasts a 30-degree Celsius temperature.
Generally speaking, classification in data mining refers to the way a data mining system is developed. It means that a generic data mining system may not be the best solution for a domain-specific mining task. Depending on the complexity of the problem, you may need to use a domain-specific approach for better results. One of the most crucial outcomes of data mined datasets is pattern identification. However, these algorithms must go through various types of data to produce the best outcomes.
When it comes to big data, classification is the best way to analyze the information. A large dataset can be extremely complex and requires specialized algorithms that are highly adaptable. By categorizing data, you can create more precise predictions. The objective of classification is to relate a variable to an observation. Then, a machine learning algorithm can find the relationship between the two. This information will be used in a database to predict the behavior of a given group of people.
In data mining, the process of classification involves labeling data and grouping similar data instances into different categories. Once you have labelled the data, you can create a classifier model that will identify the patterns and trends in the data. The data will be organized into categories according to the attributes. There are many types of models in data mining. Using a classifier will automatically classify the data based on the input and the desired outcome.
Once you have a data mining system, you can start identifying the various factors that make up the data. First of all, you must decide which variables are important to your business. In data mining, a classification system is a series of acknowledgements and data instances. Using this information, you can predict the behavior of a particular group. Creating a classification model is the key to analyzing the data and extracting patterns from it.
A data mining system should be able to classify different kinds of data. For example, it can classify emails based on their subject line. The goal of this classification is to determine whether the email is spam. This is very important for spam prevention. For example, a classification system should recognize the type of email received by the recipient. Then, it will classify the content of the email. In data mining, the input and output variables are classified into categories.
The definition of classification in data mining:
The definition of classification in data mining is simple: it is the process of predicting a group's membership. For example, if you have a data mining system that classifies e-mails, it will classify them into categories. Similarly, if the data is related to a continuous variable, it will be classified according to its value. The goal of the process is to find a relationship between the variables.






